
Abstract
Recent advancements in diffusion models have notably improved the perceptual quality of generated images in text-to-image synthesis tasks. However, diffusion models often struggle to produce images that accurately reflect the intended semantics of the associated text prompts. We examine cross-attention layers in diffusion models and observe a propensity for these layers to disproportionately focus on certain tokens during the generation process, thereby undermining semantic fidelity. To address the issue of dominant attention, we introduce Attention Regulation, a computation-efficient on-the-fly optimization approach at inference time to align attention maps with the input text prompt. Notably, our method requires no additional training or fine-tuning and serves as a plug-in module on a model. Hence, the generation capacity of the original model is fully preserved. We compare our approach with alternative approaches across various datasets, evaluation metrics, and diffusion models. Experiment results show that our method consistently outperforms other baselines, yielding images that more faithfully reflect the desired concepts with reduced computation overhead.
Examples of Text-to-Image Generation with Attention Regulation










How does it work?
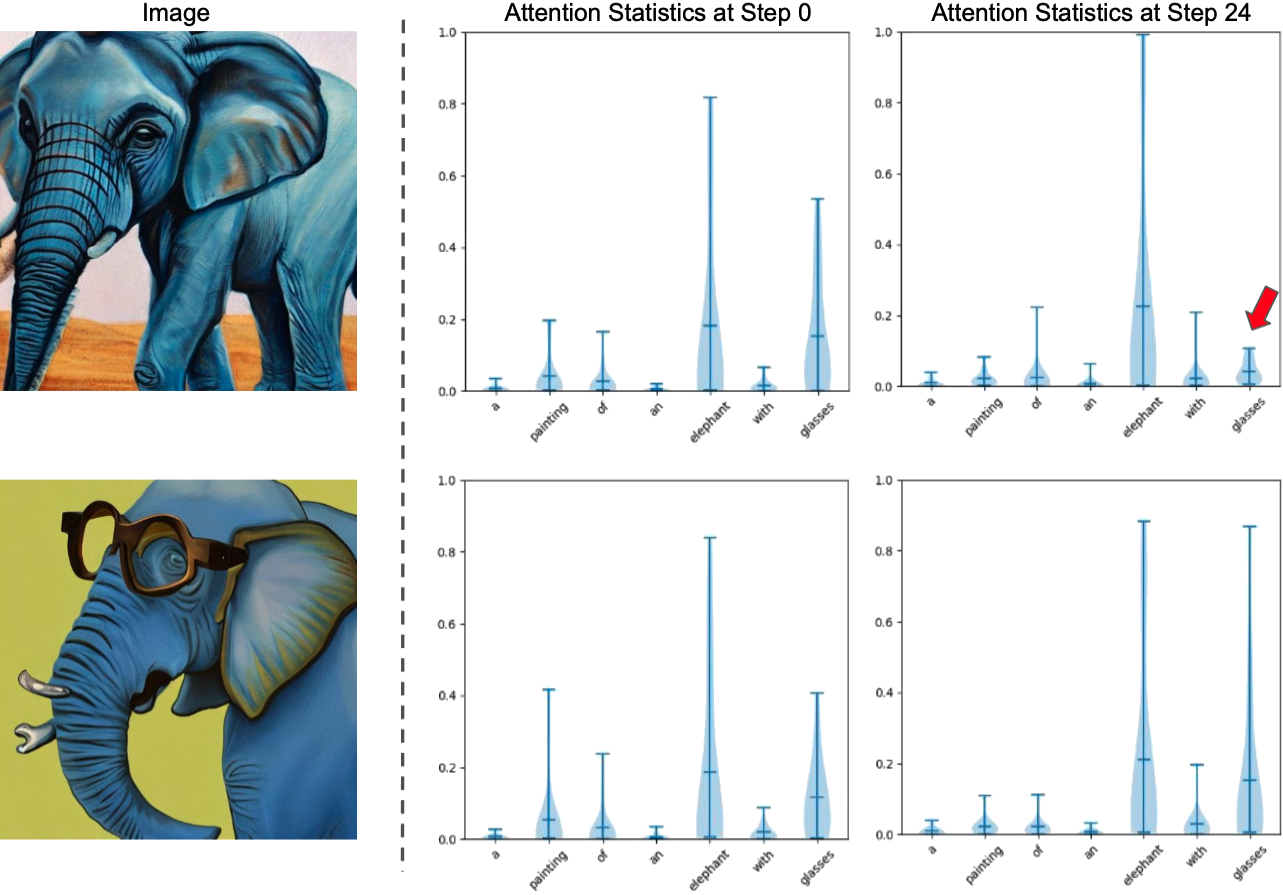
We observe that the issue of catastrophic neglect can be explained by the cross-attention values of target tokens. As seen from the figure above, in the first row, where the glasses are missing, the average cross-attention value of the glasses token is significantly lower than that of the elephant token. Conversely, in the second row, where the glasses are present, the average cross-attention value of the glasses token is significantly higher, on par with the elephant token. This leads us to hypothesize that the cross-attention values of the target tokens are crucial in determining the presence of the target objects in the generated images.
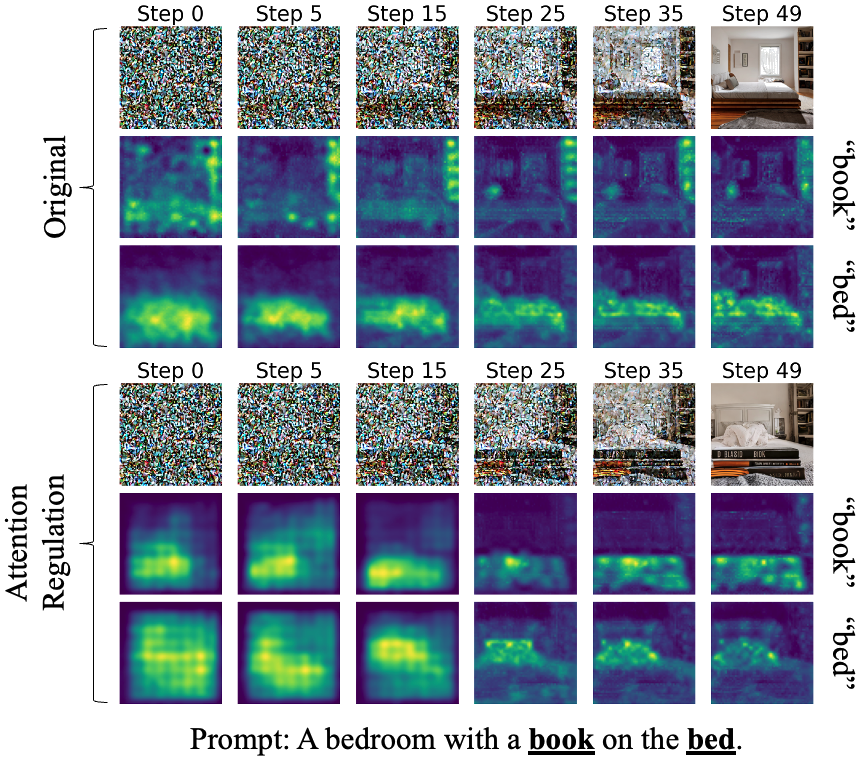
Text conditioning in Stable Diffusion is performed via the cross-attention mechanism. We can consider the cross-attention values of each target
token as a 2D spatial map. Intuitively, our Attention Regulation approach encourages the attention maps of each target token to be similar in the sense
that they should all have some region of high attention and the proportion of such high attention regions should be similar across all target tokens.
Given a prompt (e.g., "A bedroom with a book on the bed"), we extract the target tokens (book, bed).
Then, we apply a set of different 2D smoothed Gaussian kernals to the cross-attention values, guided by an optimisation process that is aligned
with the goal of having the attention maps of the target tokens to be similar.
The details of the Gaussian kernels used and the optimisation process can be found in the paper.
Comparisons with Other Approaches
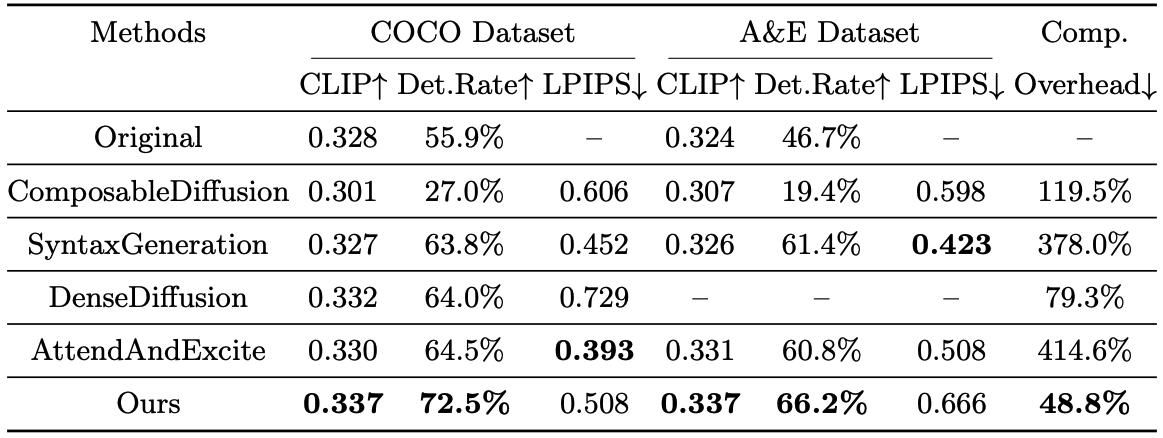
We provide a quantitative comparisons with 5 other approaches on the two different datasets, namely the COCO dataset and the Attend-And-Excite dataset.



